I/O Management and Disk Scheduling
11.1 - I/O Devices
I/O devices categories
Human readable - used to communicate with the user
- e.g. printers, display, keyboard etc.
Machine readable - used to communicate with electronic equipment
- e.g. disk drives, USB keys, controllers etc.
Communication - communicate with remote devicese
- e.g. modems, digital line drivers etc.
Key concepts
Data rate - orders of magnitude in terms of data transfer rates of devices
Application - the use to which a device is put has an influence on the software and policies in the OS and supporting utilities
- File management software for a storage disk
- Disk space for pages requires virtual memory scheme
Complexity of control - the complexity of the I/O modules that controls the different devices
- e.g. Disk requires a more complex control interface than a printer
Unit of transfer - data may be transferred as a stream of bytes or characters (terminal I/O) or in larger blocks (disk I/O)
Data representation - different data encoding schemes are used by different devices
- Difference in code and parity conventions
Error conditions - nature of errors, way they are reported, consequences, and the available responses are different in different devices
11.2 - Organization of the I/O Function
Three techniques of waiting for I/O
Programmed I/O - the processor issues an I/O command, on behalf of a process, to an I/O module; the process then busy waits for the operation to be completed before processing
Interrupt-drive I/O - the processor issues an I/O command on behalf of a process
- If the I/O instruction from the process is nonblocking, then the processor continues to execute instructions from the process that issued the I/O command
- If the instruction is blocking, then the next instruction that the processor executes is from the OS, which will put the current process in a blocked state and schedule another process
Direct memory access (DMA) - a DMA module controls the exchange of data between main memory and an I/O module
- The processor sends a request for the transfer of a block of data to the DMA module and is interrupted only after the entire block has been transferred

Evolution of the I/O Function
- The processor directly controls a peripheral device
- A controller or I/O module is used; Processor uses programmed I/O without interrupts
- Interrupts deployed
- I/O module given direct control of memory via DMA
- Enhanced I/O modules that acts like a separate processor (I/O Channel). It handles the instructions without processor intervention
- I/O module has it's own memory (I/O Processor), allowing it to control a large set of I/O devices
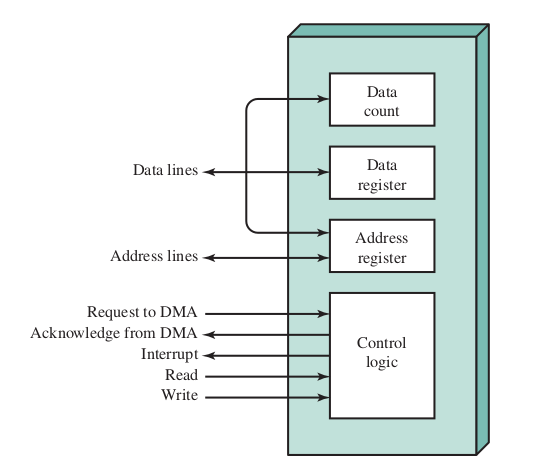
Direct Memory Access
- The DMA module mimicks the processor and take over the control of the system
- The processor sends information to the DMA module when it wants to read a block of data
- Read or write (read/write control line)
- Address of the I/O device (data lines)
- Starting location in memory (data lines, stored in the DMA register)
- Number of words (data line, stored in data cuont register)
- The DMA module then transfers the data without the involvement of the processor. It sends an interrupt to the processor after the transfer is done.
DMA Block
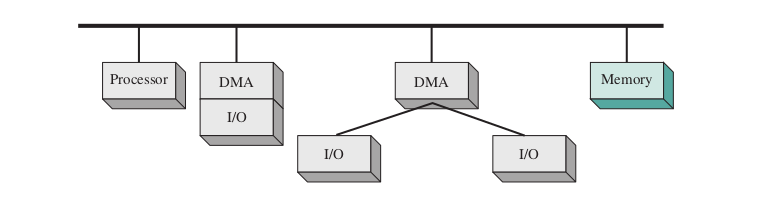
DMA Configurations

- All module share the same bus
- Use programmed I/O to exhange data between memory and an I/O module through the DMA module
- Inexpensive but inefficient
- Integrates DMA and some I/O functions using separate paths aside from the system bus
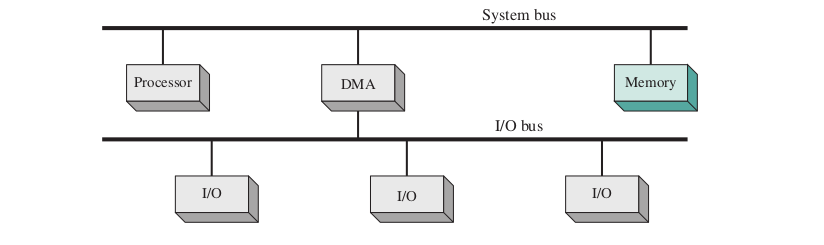
- Use a dedicated I/O bus
- One I/O interface in the DMA module
- Expandable
11.3 - Operating System Design Issues
Design Objectives
Efficiency - I/O module is usually the bottleneck in the system
Generality - it's more desirable to handle all devices in a uniform matter
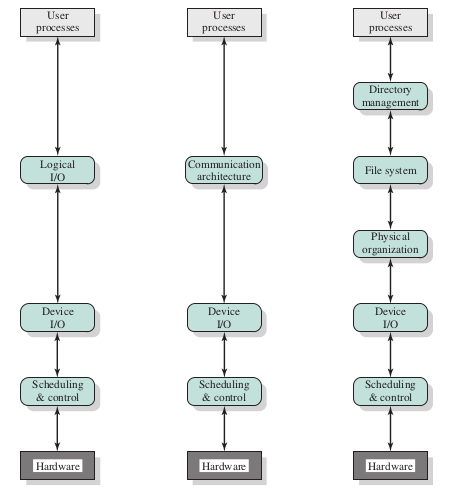
Local Structure of the I/O Function
- A hierarchical structure
Layers that involved in communicating with a local peripheral device
Logical I/O - deals with the device as a logical resource and is not concerned with the details of actually controlling the device
- Manages gneral I/O functions on half of user processes
- Simple commands
Device I/O - The requested operations and data are convereted into appropriate sequences of I/O instructions, channel commands, and controller orders
Scheduling and control - queueing, scheduling, and control of I/O operation
- Interrupts are handled in this layour
- I/O status collected and reported
Layers for communication devices
Directory management - symbolic file names are converted to identifiers that either reference the file directly or indirectly through a file descriptor or index table
File system - deals with the logical structure of files and with the operations that can be specified by user (open/close/read/write)
- Manages access rights
Physical organization - logical reference to files and records gets convereted to physical secondary storage address
- Track and sector structure
- Secondary storage space and main storage buffers
11.4 - I/O Buffering
- To avoid blocking during transfer
To make sure the system can swap out the process
Perform input transfers in advance of requests being made and to perform output transfers some time after the request is made
Block-irented device - stores information in blocks that are usually of fixed size, and transfers are made one block at a time
- e.g. disks and usb keys
Stream-oriented device - transfer data in and out as a stream of bytes, with no block structures
- e.g. terminals, printers, communication ports etc.
Single Buffer
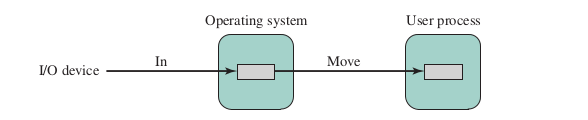
- The OS assigns a buffer in the system portion of main memory to the operation
Reading ahead / anticipated input (block-oriented devices)
- Input transfers are made to the system buffer
- When transfer is complete, the process moves the block into user space and immediately requests another block
Based on the assumption that the block will eventually be used
For a stream-oriented I/O, the buffer can be used to hold a single line (line-at-a-time I/O)
- An alternative is byte-at-a-time I/O
The system can swap the process out since the input operation is taking place in system memory rather than process memory
Complicates the OS logic as it must keep track of the assignment of system buffers to user processes
Double Buffer

- Assigning two system buffers to the operation
- Refers to as double buffering or buffer swapping
A process can transfer data to (or from) one buffer while the operating system empties (or fills) the other
Ensures that the process will not have to wait on I/O
Increased complexity
line-at-a-time I/O
- User process won't be suspended for input or output, unless the process runs ahead of the double buffers
byte-at-a-time I/O
- No advantage over a single buffer with double the length
Circular Buffer

- Improves performance of a particular process
- Improves performance for processes with rapid bursts of I/O
11.5 - Disk Scheduling

Seek time - the time for the (head) to get to the correct track
- Initial startup time and the time taken to traverse the tack that have to be crossed once the access arm is up to speed
- Under 10ms on average
Rotational delay - the time it takes for the beginning of the sector to reach the head
- 2ms on average
Access time - the time to get into the position to start read/write; seek time + rotational delay
Transfer time - time required for the read/write process
T = transfer time
b = number of bytes to be tranfers
N = number of bytes on a track
r = rotation speed (rps)
Total average access time
Disk Scheduling Policies
Random scheduling - select random I/O requests from the queue; used to benchmark other methods
First In First Out
- Processes requests from the queue in sequential order
- Fair
- Performs well when many requests are to clustered file sectors or few processes requires access
- Does not perform well when many processes are competing for the disk
- Often approximate random scheduling in performance
Priority
- Control of scheduling is outside the control of disk management software
- Not intended to optimize disk utilization
- Short batch jobs and interactive jobs are given higher priority than longer jobs
- Long jobs may face starvation
Last in First Out
- Taking advantage of locality in a transaction-processing systems
- Giving the device to the most recent user
- Requests may face starvation in a busy system
Shortest Service Time First
- Selects disk I/O requests that require the least movement of the disk arm from its current position
- Minimize seek time
- Random tie-breaking algorithm may be needed to resolve cases of equal distances (in the opposite direction)
- Better performance than FIFO
Scan
- The arm can only move in one direction until it reaches the last track or there are no more requests in that direction (LOOK policy)
- Prevents starvation
- Performs similarily to SSTF on average
- Biased against the area most recently traversed (not utilizing locality as well as SSTF)
C-Scan
- Restricts scan to one direction only
- Upon reaching the last track, the arm returns to the opposite end of the disk and the scan begins again
- Reduces the maximum delay experienced by new requests
N-Step-SCAN and FSCAN
- To prevent a process from monopolizing the arm by repeatly requesting a particular track
- N-step-SCAN - segments the disk request queue into subqueues of length N.
- Subqueues are proceseed one at a time using SCAN
- Requests are added to other queues when the current queue is being processed
- FSCAN - use two subqueues
- All of the requests are in one of the queues when a scan begins
- All new requests during the scan enters the other queue
11.6 - RAID
- A set of physical disk drives viewed by the OS as a single logical drive
- Data are distributed across the physical drives of an array in a scheme known as striping
- Redundant disk capacity is used to store parity information, which guarantees data recoverability in case of a disk failure
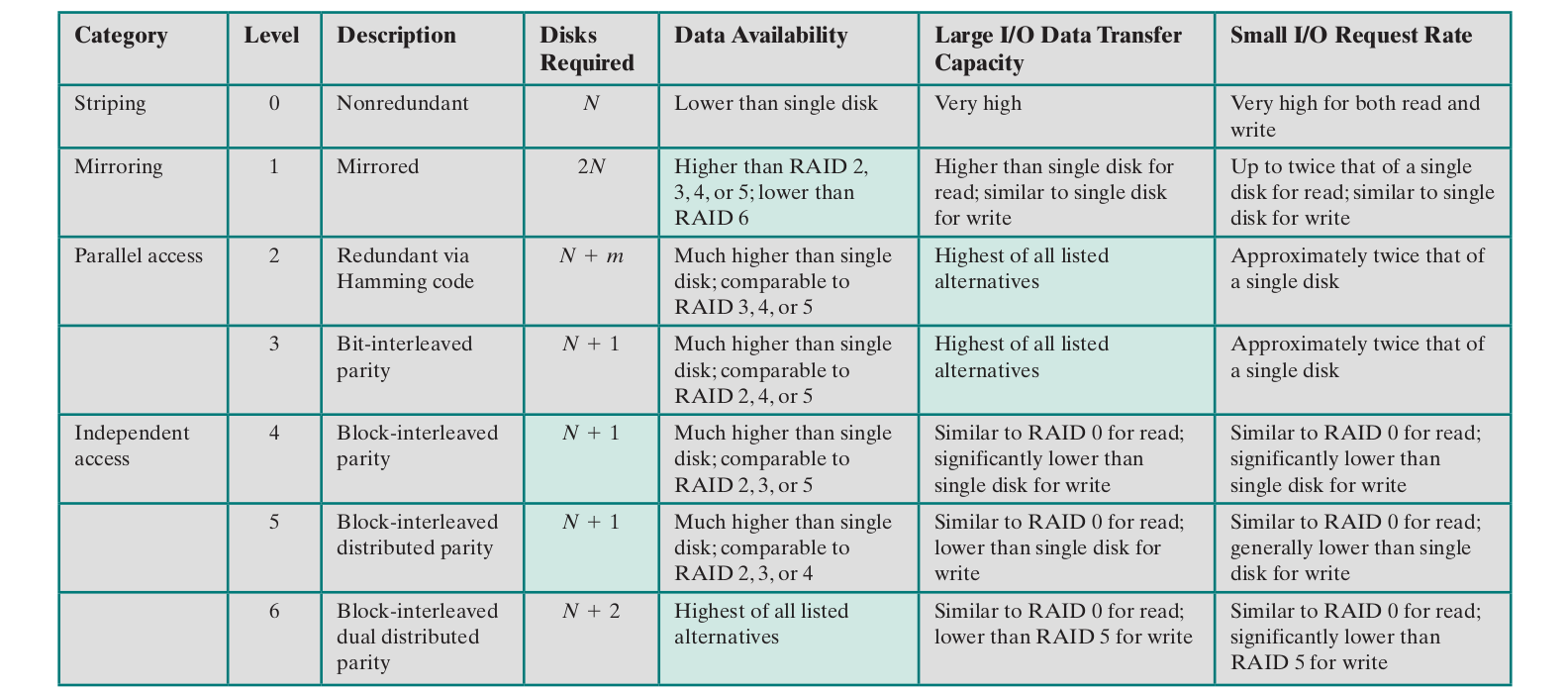
RAID 0
- User and system data are distributed across all of the disks in the array
- Data is divided in strips and distributed across the disks in a round robin like way
- stripe - a set of logically consecutive strips that maps exactly one strip to each array member
- High transfer capacity (read/write)
- High I/O request rate
- No redundancy
RAID 1
- Each logical strip is mapped to two separate physical disk (all data duplicated)
- Read request can be served by either of the two disks, the one with lower seek time is selected
- Write request updates both corresponding strips in parallel (dictated by the slower disk)
- Easy data recovery
- Always need twice the physical disk space of the logical disk
- High I/O request rates for reads
RAID 2
- Data striping used
- Strips are very small
- Error-correcting code calculated across corresponding bits on each data disk, bits of the code are stored in the corresponding bit positions on multiple parity disks
- Costly (although less than RAID 1)
- Numbe rof parity disks is proportional to the log of the number of data on disks
- Effective in environments where disk errors occur
RAID 3
- Similar to RAID 2 but only one parity disk is required
- Data can be recovered by accessing data on the parity disk and remaining disk in the case of a disk failure
- Using an XOR function on the bits
- High data transfer rates
- Only one I/O requests can be executed at a time
RAID 4
- Uses independent access array to allow each disk to operate independently
- Independent I/O requests can be satisfied in parallel
- High I/O requests for read
- Large data strips
- Bit-by-bit parity strip stored on the parity disk
- Write penalty when I/O request of small size is performed
- Need to update user data and corresponding parity bits
RAID 5
- Similar to RAID 4
- Parity strip is distributed on all disks in a round-robin scheme
- Avoids I/O bottle neck of the single parity disk
RAID 6
- Two different parity calculations are performed and stored in separate blocks on different disks
- Thus requires 2 parity disks
- Very high data availbility
- Can tolerate up to 2 disk failures
- Good read performance
- Significant write penalties compared to RAID 5
11.7 - Disk Cache
- A buffer in main memory for disk sectors
- Similar to cache memory but for disk data
Data Delivery
How to bring data to the request process
Transfer the data directly
- Pass a pointer to the process that references the desired data in the disk cache
Replacement Strategy
- Least recently used (LRU) is the most common strategy used
- Least frequently used (LFU) is another possibility
- Implemented using a counter
- A technique known as frequency-based replacement is used to overcome locality problems of LFU
- Uses a stack
- When there is a cache hit, the referenced block is moved to the top of the stack
- If the block was already in the new section, its reference count is not incremented; else it increments by 1
- The block with the smallest reference count in the old section is chosen for replacement; the least recently used such block is chosen in the event of a tie
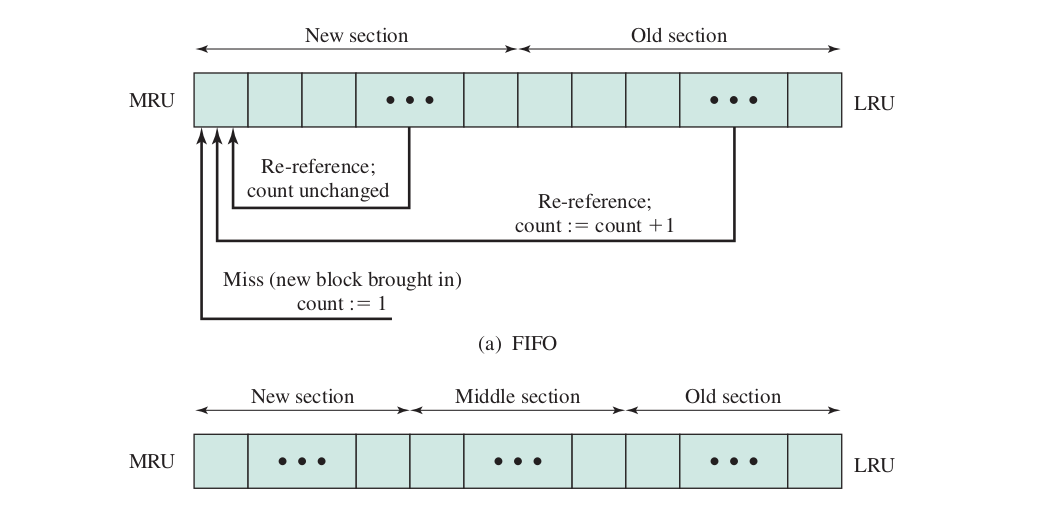
- Only achieves small performance improvement over LRU
- Inadequate interval for blocks to build up their reference counts even if they are relatively frequently referenced
- Can divide to three sections for improved performance (new, middle, old)
11.9 - Linux I/O
Disk Scheduling
- Uses the Linux Elevator by default
- A variation on the LOOK algorithm
- Augmented by the deadline I/O scheduler and the anticipatory I/O scheduler
The Elevator Scheduler
Maintains a single queue for read/write requests
- Keeps the list of requests sorted by block number
If the request is to the same on-disk sector or an adjacent sector to a pending request in the queue, then the existing request and the new request are merged into one request
- If a request in the queue is sufficiently old, the new request is inserted at the tail of the queue
- If there is a suitable location,the new request is inserted in sorted order
- If there is no suitable location, the new request is placed at the tail of the queue
Deadline Scheduler
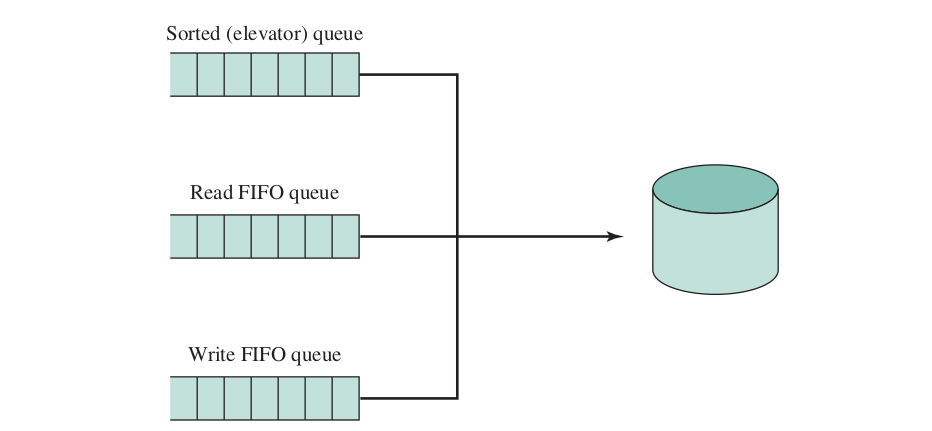
- Uses three queues
- Each incoming request is placed in the sorted elevator queue
- Also placed at the tail the Read/Write FIFO queue depends on the type of the request
- An expriation time for each requests
- Normally the scheduler dispatches from the sorted queue
- The request is removed from all queues once satisfied
- When the request at one of the head of the FIFO queues expires, the scheduler dispatches from that queue and processes the expired request along with the next few requests from the queue
- Overcomes problems with starvation for distant blocks requests and the last of distinction between read and writes
Anticipatory I/O Scheduler
- Original elevator and deadline scheduler performances poorly when there are numerous synchronous read requests
- The anticipatory I/O scheduler is superimposed on the deadline scheduler
- Causes a delay of 6ms when a read request is dispatched to see if the application that issued the last read request will issue another read request to the same region of the disk (locality)
- If such request exists it gets processed immediately
- Causes a delay of 6ms when a read request is dispatched to see if the application that issued the last read request will issue another read request to the same region of the disk (locality)
Linux Page Cache
- Before Linux 2.2 the kernel maintained a page cache for reads and writes from regular file system and for virtual memory pages, and a seperate buffer cache for block I/O
After Linux 2.4 there is a unified page chache that is involved in all traffic between disk and main memory
A collection of dirty caches can be ordered properly and written out efficently onto disk
Due to temporal locality, pages in the page cache are likely to be referenced again before they are flushed from the cache, thus saving a disk I/O operations
Dirty pages are written back to disk in two situation
- When free memory falls below a specified threshold
- When dirty pages grow older than a specified threshold