Summary Notes for Quiz 3
Includes Chapter 8-10
Virtual Memory (Chapter 8)
Terminology

8.1 - Hardware and Control Structure
- All memory references within a process are logical address that are dynmaically translated into physical address at run time; Processes may occipy different memory spaces during the course of the execution
- A process may be broken into number of pieces (pages or segments); Does not need to be contiguou
Residence set - the portion of a process that is in the main memory at any gi
Virtual memory - a larger memory allocated to programmer located on the disk
Overview of paginging and Segmentation

Thrashing - when the system spends most of its time swapping pieces of memory
- When the system switches out a piece of a memory immediately before it's used
Principle of Locality - program and data references within a process tend to cluster
Address Structure for Paging

- The frame numer indicates the location of the current page in the main memory
- P - indicates whether the corresponding page is present in the main memory or not
- Frame number is included if the page is present
- M - indicates whether the contents of the corresponding page have been altered since the page was last loaded into the main memory
Page Table Structure

- Usually there is one page table per process, however processes can occupy large amounts of virtual memory which results in the page table occupying large amounts of memory
- To overcome the problem, most virtual memory schemes also stores the page table in virtual memory
Two-Level Page Table

- A page directory contains entry points to the pages tables
- The page tables points to the actual memory address space
![]()
Inverted Page Table
- A alternative to mitigate the fact that the size of page tables is proportional to that of the virtual address space
- Indexes page table entries by frame number rather than by virtual page number

Structure of PTE:
Page number - the page number portion of the virtual address
Process identifier - The process that owns this page; Can be used to identify a page within the virtual address with the page number
Control bits - The field includes flags, such as valid, referenced, and modified; protection and locking information
Chain pointer - null if there are no chained entries for this entry. If there is a chain entry, it contains the index value of the next entry in the chain
Translation Lookaside Buffer
- Special high-speed cache for page table entries
- Similar to memory cache
![]()
- Retrieves the frame number and generates the real address on TLB hit
- The processor uses the page number to index the process page table and examine the corresponding page table entry on TLB miss
- Page fault - when the present bit is not set; the OS is invoked to load the needed page and update the page table
TLB Workflow:

Associative mapping - the technique in which the processor can check multiple page table entries to determine if there is a match on page number, as TLB contains only a partial set of the page table entry and direct mapping is not available
Page Size

- Smaller page sizes can produce less internal fragementation, but it means more pages are needed for a program and causing an increase in virtual memory space used by page tables
- More TLB misses
- More disk access
As page size increase the rate of page faults increase since the principle of locality is weakened, however it will reach a peak and start falling as the size of the page approaches the size of the program
The rate of page faults also falls as the number of pages contained in the main memory grows
OOP (small program and data modules) and Multithreaded applications (abrupt changes in the instruction stream) also decreases the locality of references
Segmentation
- Allows the programmer to view memory as consiting of multiple (unequal) address spaces or segments
Advantages
Simplies the handling of growing data structures
- The OS can expand or shrink the segment to accomodate varying sizes of data structures
- Segments can be moved around in the main memory by the OS
Allows programs to be altered and recomplied independently without requiring the entire set of programs to be relinked and reloaded
Can be shared among processes (e.g. utility program)
Better protection
- Easy to define privileges
Organization
- Contains the starting address of the corresponding segment in the main memory and the length of the segment
- Contains a bit to indicate whether the corresponding segment exists in the main memory
- Contains a modify bit that indicates whether the content of the segment have been altered since the segment was last read into the main memory
- Not neccessary to replace the segment if it was not altered
Address Translation Workflow
Combined Paging and Segmentation
Advantages of combining the two systems
| Paging | Segmentation |
|---|---|
| - Elimates external fragementation | - Handle growing data structures |
| - Transparent to the programmer | - Better support for modularity |
| - Fixed size; eaiser to develop complicated memory mangement algorithms | - Better data sharing / protection |
- A user's address space is broken into a number of segments
- A segment is broken up into number of fixed-size pages (equal in size to the main memory frame)
Programmer can still treat the system as segments and the OS can treat the system as fixed sized pages in different segments

Segment entires now also contains a base field, which now refers to a page tables
Present and modified bits are not need as they are handled by the pages
Protection and Sharing
- Can be referenced in the segment tables by more than one process
Protection relationships

Ring System
- A program may access only data that reside on the same ring or less privileged ring
- A program may call services residing on the same or more privileged ring
8.2 - Operating System Software
- Whether or notj to use virtual memory techniques
- The use of paging or segmentation or both
- The algorithms employed for various apsects of memory management
Overview of System Policies for Virtual Memory

Fetch Policy
- Determines when a page should be brought into main memory
Demand paging - a page is brought into main memory only when a reference is made to a location on that page
- Page faults in the beginning, the rate falls as more pages are brought into the main memory
Prepaging - pages other than the one demanded by a page fault are brought in
Placement Policy
- Determines where in real memory a process piece is to reside
- In a pure segmentation system we can use methods such as best-fit, first-fit etc.
Placement does not matter in a pure paging or paging combined with segmentation (hardware performs address translation)
Placement is a concern in nonuniform memory access (NUMA) multiprocessor
Replacement Policy
- Determnes the selection of a page in main memory to be replaced when a new page must be brought in
Resident set management
- How many page frames are to be allocated to each active process
- Should the set of pages considered for replacement only include the process that caused the page fault or all page frames in main memory
Replacement policy
- Which particular page (within the selected set) should be selected for replacement
Frame locking - Some frames in the main memory may be locked and pages stored in that frame may not be replaced
- e.g. Kernel of the OS
Basic Algorithms:
Optimal - selects for replacement that page for which the time to the next reference is the longest
- Not possible to implement, but can be a reference to other algorithms
Last recently used (LRU) - replaces the page in memory that has not been referenced for the longest time
First-in-first-out (FIFO) - treats the page frames as a circular buffer and swap them out in round-robin style
Clock policy - make uses of an extra use bit on the frame
Uses a circular buffer
When a page is first loaded into the memory the bit of that frame is set to 1
When the page is subsequently referenced the use bit is set to 1
The OS scans the buffer. If it encouters a page that has a used bit set to 1, it sets the bit to 0. If it encounters a page with the used bit set to 0, that page is selected for replacement. If every page has a value 1, all of them will be set to 0 and the OS selects the first page as the one to be replaced.
Comparing the workflow of different algorithms

Page Buffering
- Has a free page list for pages that are not modified and a modified page list for one that are
- Uses FIFO
- A replaced page is placed in one of the two buffers
- When a page is to be read in, the page frame at the head of the list is used, destroying the page that was there
- When an unmodified page is to be replaced, it remains in memory and its page frame is added to the tail of the free page list
- When a modified page is to be written out and replaced, its page frame is added to the tail of the modified page list
- Replaced pages stays in memory, which reduces the cost of replacements
Replacement Policy and Cache Size
- Cache sizes are getting larger as the locality of applications is decreasing
Resident Set Management
Resident set size is determined by
- Smaller amount of memory given to each process => more process in the memory => less swapping
- Small number of pages => higher page faults
- Allocating more memory to a process will have little effect on the page fault rate for that process at a certain point (principle of locality)
Fixed-allocation - gives a process a fixed number of frames in main memory to execute
- Number of pages determined on initial load
- When a page fault occurs one of the pages in the program must be replaced
Variable-allocation - the number of page frames allocated to a process to be varied over the lifetime of the process
- Processes with high levels of page faults are given more frames, ones with low page fault rates are given less
- Requires the OS to assess the behaviour of active processes
Replacement Scope
Can be global or local
Local replacement policy chooses only among the resident pages of the process that generated the page fault in selecting a page to replace
Global replacment policy considers all unlocked pages in main memory as candidates for replacement

Fixed allocation, local scope
- Need to determine the amount of allocation given to the process ahead of time
- If the prediction is too small the process will experience large numbers of page faults
- If the prediction is too large in general there will be too little programs in the main memory
Variable allocation, global scope
- The number of frames of the process that experiences page fault grows as time progresses
- The OS must decide which frame to replace when there are no free frames available
- Can use page buffering to counter performance problems
Variable allocation, local scope
- When a new process is loaded into main memory, allocate to it a certain number of page frames as its resident set based on certain criteria; use either prepaging or demand paging
- When page fault occurs, select the page to replace from among the resident set of the process that suffers the fault
- Reevaulate and adjust the total allocation of the process from time to time
Working set strategy - a strategy used to determine the resident set size the timing of changes
- Monitor the working set of each process
- Periodically remove from the resident set of a process those pages that are not in its working set (LRU)
A process may execute only if its working set is in main memory
The past does not always predict the future
A true measurement of working set for each process is impractical
The optimal value of is unknown and would vary in different cases
Page fault frequency (PFF) algorithm - Implemented using a used bit on each page and a counter of page references
Variable-interval sampled working set (VSWS) - evaluates the working set of a process at sampling instances based on elapsed virtual time
- In the beginning of the sampling interval all used bits are set to 0
- In the end only the ones referenced during the interval will have their used bit set to 1. These pages are retained int he resident set in the next inerval
- Any faulted pages are added to the interval
Three parameters of VSWS
- M: the minimum duration of the sampling interval
- L: the maximum duration of the sampling interval
- Q: the number of page faults that are allowed to occur between sampling instances
Workflow of VSWS
- If the virtual time since the last sampling instance reaches L, then suspend the process and scan the used bits
- If prior to L, Q page fault occurs
- If time is less than M, then wait until the elapsed time reaches M to suspend the process and scan the used bits
- If time is greater than or equal to M, suspend the process and scan the use bits
Cleaning Policy
- Determines when a modified page should be written out to secondary memory
Demand cleaning - a page is written out to secondary memory only when it has been selected for replacement
Precleaning - writes modified pages before their page frames are needed so that pages can be written out in batches
- Can implement page buffering to decouple the cleaning and replacement process
Load Control
- Determine the number of processes that will be resident in main memory
Multiprogramming Level
- An increase in the multiprogramming level results in more processor utilization, but a one point the resident set would become inadequate and thrashing occurs
- L = S criterion - adjusts the multiprogramming level so that the mean time between faults equals the mean time required to process a page fault
- Can also adapt the clock page replacement
Process Suspension
- To decrease the degree of multiprogramming, some of the current resident processes must be suspended
- Lowest-priority process - a scheduling policy decision
- Faulting process - least performance suffering; immediate payoff
- Last process activated - least likely to have its working set resident
- Process with the smallest resident set - least future effort to reload; penalizes programs with strong locality
- Largest process - obtains the most free frames
- Process with the largest remaining execution window
8.3 - Unix and Solaris Memory Management
Paging system
Page table - one or more page table per process, with one entry for each page in virtual memory for that process
Disk block descriptor - an entry that describes the disk copy of the virtual page
Page frame data table - describes each frame of a real memory and is indexed by frame number
Swap-use table - one for each swap device, with one entry for each page on the device
Page replacement
- Page frame data table is used for page replacement
- Uses the two-handed clock algorithm
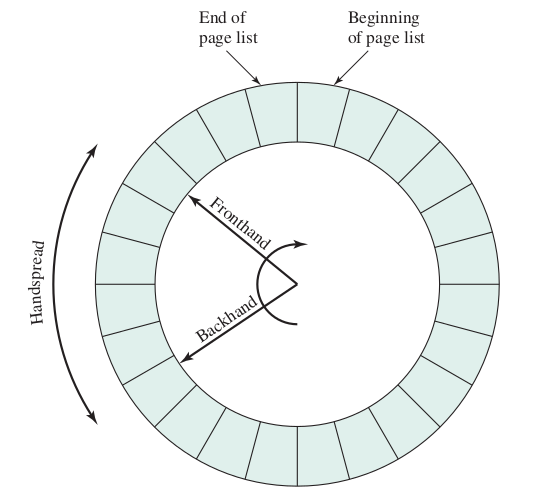
Scanrate - the rate at which the two hands can scan through the page list, in pages per second
Handspread - the gap between the front and backhand
- As the amount of free memory shrinks, the clock hands move more rapidly to free up more pages
Kernel Memory Allocator
- Generates and destroys small tables and buffers frequently during the course of execution
- When dealing with blocks significantly smaller than the typical machine page size the paging mechanism would be inefficient for dynamic kernel memory allocation
- A modification of the buddy system is used, called the lazy buddy system
- Defers coalescing until it seems likely that it is needed, then coalesces as many blocks as possible
8.4 - Linux Memory Management
Virtual Memory Addressing
- Uses a three-level page table structure
- Page directory - an active process has a single page directory the size of one page
- Each entry in the directory points to one page of the page middle directory
- Must be in main memory for an active process
- Page middle directory
- Each entry points to one page in the page table
- May span multiple pages
- Page table
- May also span multiple pages
- Page directory - an active process has a single page directory the size of one page
Address Translation
![]()
Page Replacement Algorithm
- Uses the clock algorithm before 2.6.28
- Uses a split LRU algorithm after 2.6.28

- The first time a page on the inactive list is accessed, the PG-referenced flag is set
- The next time the page is accessed, it is moved to the active list
- If the second access doesn't happen soon enough PG_referenced is reset
- Two timeouts are also required to move active pages to the inactive list
Kernel Memory Allocation
- Allocate and deallocate frames for particular uses
- Based on the page allocation mechanism used for user virtual memory management
- Uses the buddy system
- Uses slab allocation
Scheduling (Chapter 9)
9.1 - Types of Processor Scheduling
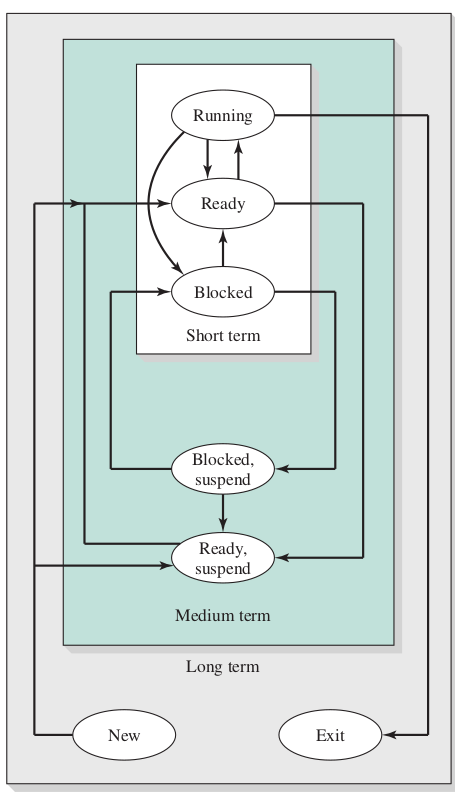
Long-Term Scheduling
- Determines which programs are admitted to the system for processing
- Controls the degree of multiprogramming
- The decision of which job to admit can be a simple first come first served method, or a tool to manage system performance
- e.g. keep a mix of processor-bound and I/O-bound processes
Medium-Term Scheduling
- Part of the swapping function
- Based on the need to manage the degree of multiprogramming
- The swapping-in decision will consider the memory requriements of the swapped-out processes
Short-Term Scheduling
- Also known as the dispatcher
- Invoked whenever an event occurs that may lead to the blocking of the current process or the need to preempt a running process in favour of another
- e.g. Clock interrupts, I/O interrupts, OS calls, signals etc.
Queueing Diagram for Scheduling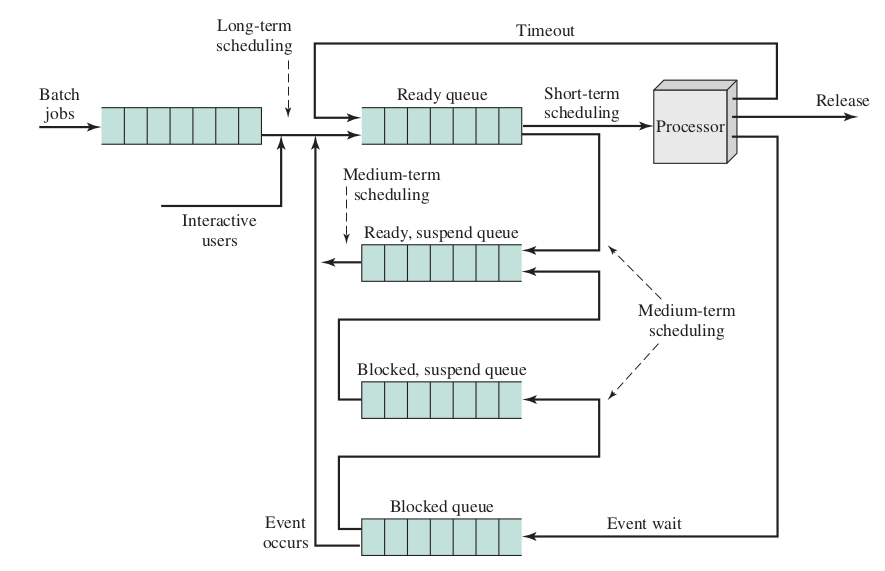
9.2 - Scheduling Algorithms
Short-Term Scheduling Criteria
User-oriented criteria - relate to the behaviour of the system as perceived by the individual user or process
- e.g. response time
System-oriented criteria - effective and efficient utilization of the processor
- e.g. throughput (rate at which processes are being processed)
Performance-related criteria - quantitative and can be readily measured
Non-performance-related criteria - qualitative
- e.g. predicatbility
 The Use of Priorities
The Use of Priorities
- Each process is assigned a priority
- The scheduler always choose a process of higher priority
- In a pure priority scheduling scheme processes with lower-prority may suffer starvation
Alternative Scheduling Policies
 w = time spent in the system so far (waiting)
w = time spent in the system so far (waiting)
e = time spent in execution so far
s = total service time required by the process
Selection function - function that determines which process is selected next for execution
Decision mode - specifies the instants in time at which the selection function is excercised
- Nonpreemptive - when a process enters a running state it will not be interrupted until it terminates or blocks itself to wait for I/O or request some OS service
- Preemptive - running process may be interrupted and moved to the ready state
Turnaround time (TAT) - the resident time; the total time that the item spends in the system
First-Come-First-Served (FIFO)
- When a process becomes ready it joins the ready queue
- When the currently running process ceases to execute, the process that has been in the ready queue the longest is selected for running
- Performs better for long processes
- Favours processor-bound processes over I/O-bound processes
- Often combined with a priority system to improve performance
Round Robin
- Use preemption based on a clock
- A clock interrupt is generated at periodic intervals and the currently running process is placed in the ready queue to allow the next ready job to be executed
- Also known as time slicing
- Need to determine an optimal time quantum
- Effective in general-purpose time sharing system or transaction processing system
- Drawback: I/O-bound process has a shorter processor burst than a processor-bound processes
- I/O-bound process executes for a very short time and gets blocked on waiting for I/O, while processor-bound processes generally uses the full time quantum
Virtual Round Robin (VRR)
- Adds an FCFS axuiliary queue to which processes are moved after being released from an I/O blocked
- Processes in the auxiliary queue gets priority
- Processes dispatched from the auxiliary queue runs no longer than (time quantum) - (time of last execution)
Shortest Process Next
- The process with the shortest expected processing time is selected next
- Better response time, reduced predictability for long processes
- Long processes may face starvation
- Need to calculate the process time
Highest Response Ratio Next
- Minimize the ratio of turnaround time to actual service time
- Accounts for the age of the process
- While shorter jobs are favoured, aging without service increases the ratio so that a longer process will eventually get past competing shorter jobs
Feedback
- Uses a dynamic priority mechanism
- A new process starts with the highest priority, when it returns to the ready state, it moves down the priority level
- Processes with the lowest priority reenters the lowest priority queue until it finishes execution
- Newer, shorter processes favoured over longer, older processes
- Also known as multilevel feedback
Fair-Share Scheduling
- How to schedule collections of processes owned by different users in a multi-user enviroment
- Each user has a "weight" which denotes the amount of resources that the user is allocated within the system
Fair-share scheduler (FSS)
- Considers the execution history of a related group of processes, along with the individual execution history of each process in making scheduling decisions
- Divides the user community into a set of fair-share groups and allocates a fraction of the processor resource to each group
9.3 - Traditional Unix Scheduling
- Uses multilevel feedback using round robin within each of the priority queues
- Uses one-second preemption
- Priority is based on process type and execution history
- Base priority divides all processes into fixed bands of priority levels, in decreasing order of priority they are
- Swapper
- Block I/O device control
- File manipulation
- Character I/O device control
- User processes
- Provides the most efficient use of the I/O devices
Multiprocessor, Multicore and Real-Time Scheduling (Chapter 10)
10.1 - Multiprocessor and Multicore Scheduling
Loosely coupled/Distributed multiprocessor/Cluster - each processor has its own main memory and I/O channels
Functionally specialized processors - a general-purpose, master processor controls a collection of specialized processors that provide services to the master processor
Tightly coupled multiprocessor - a set of processors that share a common main memory and are under the integrated control of an operating system
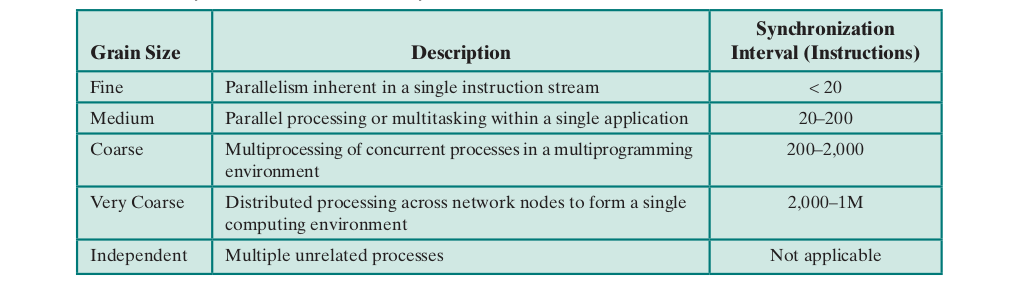
Granularity
- Frequency of synchronization between processes in a system
 Independent Parallelism
Independent Parallelism
- No explicit synchronization among processes
- An example would be time-sharing system
- The multiprocessor provides the same service as a multiprogrammed uniprocessor
Coarse and Very Coarse-Grained Parallelism
- Very gross level of synchronization
- Multiprocessing system provides better support for frequent communication, distributed system can provide good support for infrequent communications
Medium-Grained Parallelism
- High degree of coordination and interaction between the threads of a single application
- Need better scheduling function
Fine-Grained Parallelism
- Refer to the table
Design Issues
Assignment of Processes to Processors
- Static assignment to one processor requires a shor-term queue maintained for each processor
- Less overhead for scheduling function
- Allow group/gang scheduling
- One processor could be idle with others having a backlog
- A global queue can be used to mitigate the problem
Dynamic load balancing allows threads to be moved from one to another processor
- Linux uses this approach
Master/slave architecture - The master runs key kernel functions of operating systems, and schedules jobs. The other processor runs only user programs
- Simple and requires little enhancement to a uniprocessor OS
- Failure of master can bring down the system
- Master can be performance bottleneck
Peer architecture - Kernel can execute on any processor, and each processor does self-scheduling from the pooil of available processes
- Complicates the OS
The Use of Multiprogramming on Individual Processors
- In a multiprocessor environment, it is not neccessarily the best to keep all the processors busy, but the best average performance for applications
- An application that consists of a number of threads may run poorly unless all of its threads are available to run simultaneously
Processing Dispatching
- The actual selection of a process to run
Thread Scheduling
Load sharing - each processes selects thread from a global queue when idle
Allocated on a less permanent basis than load balancing
First-come-first-served (FCFS) - when a job arrives, each of its threads is placed consecutively at the end of the shared queue. The processor picks the next ready thread when it's idle and executes it until completion or blocking
- Smallest number of threads first - Highest priority given to threads from jobs with the smallest number of unscheduled threads
- Preemptive smallest number of threads first - Highest priority given to jobs with the smallest number of unscheduled threads. Arriving jobs with higher priority will preempt threads belonging to the scheduled job
| Advantages | Disadvantages |
|---|---|
| - Load distributed evenly across the processors, no idle processors | - The central queue occupies a region of memory that must be accessed in a manner that enforces mutual exclusion. May become a bottleneck when many processors look for work at the same tim |
| - No centrialized scheduler is needed | - Preempted threads are unlikely to resume execution on same processor (inefficient for processors with local cache) |
| - Global queue can be organized an accessed by multiple methods | - Unlikely that all of the threads of a program will gain access to processors at the same time |
Gang scheduling - a set of related threads is scheduled to run on a set of processors at the same time, on a one-to-one basis
- Useful for medium-grained to fine-grained parallel applications whose performance severly degrades when any part of the application is not running while other parts are ready to run
- Advantages
- Less synchronization blocking and process switching if the processes in the group requires high lovels of coordination
- A single scheduling decision affects a number of processors and processes at one time, reducing scheduling overhead
Dedicated processor assignment - dedicate a group of processors to an application for the duration of the application
- Little overall cost in systems with large numbers of processors in contrast to the performance boost to individual applications
- Eliminates process switching
Dynamic scheduling - the number of threads in a process can be altered during the course of execution
- OS responsible for parititoning the processors among the jobs
- Each job uses the processors currently in its partition to execute some some subset of its runnable tasks by mapping these tasks to threads
When a job requests one or more processors
If there are idle processors, use them to satisfy the request
- Otherwise, if the job making the request is a new arrival, allocate it a single processor by taking one away from any job currently allocated more than one processor
- If any portion of the request cannot be satisfied, it reamins outstanding until either a processor becomes available for it or the job rescinds the request
- Upon the release of one or more processors, scan the current queue of unsatisfied requests for processors. Assign a single processor to each job in the list that currently has no processors. Then scan the list again, allocating the rest of the processors on an FCFS basis
10.2 - Real-Time Scheduling
Hard real-time task - task that must meet it's deadline
Soft real-time task - task that has a deadline that's desirable but not mandatory
Aperiodic task - task that has a deadline by which it must finish or start; may have a constraint on both start and finish time
Periodic task - repetitive; "once per period T"
Characteristics of Real-Time Operating System
Determinism - the degree of a system performing operations at fixed, predetermined times or time invervals
Responsiveness - How long after acknowledgment of an interrupt, it takes an operating system to service the interrupt
- The amount of time required to initially handle the interrupt and begin execution of the ISR
- The amount of time required to perform the ISR
- The effect of interrupt nesting
User control - allow the user fine-grained control over task priority
- Be able to distinguish between hard and soft tasks and to specify relative priorities within each class
Reliability
- System failure may result in catastrophy
Fail-soft operation - the ability of the system to preserve as much capability and data as possible in case of a failure
Real-Time Scheduling
Static table-driven approaches - perform a static analysis of feasible schedules of dispatching; produces a schedule that determines when a task must begin execution
- Applicable to periodic tasks
- Predicable but inflexible (changes in tasks requires the schedule to be redone)
Static priority preemptive approaches - static analysis; no schedule is produced; the analysis is used to assign priorities to tasks
- Tranditional priority driven preemptive scheduler can be used
- Priority related to the time constraints associated with each task
- Rate monotonic algorithm
Dynamic planning-based approaches - feasibility is determined at runtime (dynamically) rather than offline prior to the start ot execution (statically)
- When a task arrives, before execution, makes a achedule that contains the previously scheduled tasks as well as the new arrival
- If the new arrival's deadline can be satisfied, the reschedule is revised
Dynamic best effort approaches - No feasibility analysis is performed; system tries to meet all deadlines and aborts any started process whose deadline is missed
- Typically uses earliest deadline scheduling
- Unclear whether the deadline will be meat until it arrives or the task finishes execution
- Easy to implement
Deadline Scheduling
Maximize the number of tasks completing at the most valuable time (not too early and not too late)
Uses the following aspects of the task for scheduling
- Ready time - time at which task becomes ready for execution
- Starting deadline - time by which a task must begin
- Completion deadline - time by which a task must complete execution
- Processing time - time required to execute the task
- Resource requirements - set of resources (other than processor) that is required during the lifetime of the process
- Priority - relative importance of the task
- Subtask structure - a task may be decomposed to a mandatory task and an optional task
Rate Monotonic Scheduling
- HIghest priority is given the task with the shortest period
Priority Inversion
- When the system force a higher-priority task to wait for a lower-priority task under certain circumstances
- When the lower priority task locks a resource and the higher priority task tries to do the same
Unbounded priority inversion - when the duration of a priority inversion depends not only on the time required to handle a shared resource but also on the unpredictable actions of other unrelated tasks
Priority inheritance - when a lower-priority task inherits the priority of any higher-priority task pending on a resource they share
Priority ceiling - a priority is associated with each resource, and it's always one level higher than the priority of its highest-priority user. The scheduler then dynamically assigns this priority to any tasks that accesses the resouce. Once the task finishes withe resource, its priority returns to normal